如果使用文件滚动更新选项,则在达到最大文件大小时,SQL Server 会关闭当前文件并创建一个新文件。新文件与原文件同名,但是文件名后将追加一个整数以表示其序列。例如,如果原始跟踪文件命名为 filename_1.trc,则下一跟踪文件为 filename_2.trc,依此类推。如果指定给新滚动更新文件的名称已经被现有文件使用,则将覆盖现有文件,除非现有文件为只读文件。默认情况下,将跟踪数据保存到文件时,会启用文件滚动更新选项。
指定有最大行数的跟踪在达到最大行数时,会停止将跟踪信息保存到表。每个事件构成一行,因此该参数可设置收集的事件数的范围。设置最大行数使得无人参与的跟踪运行起来更加方便。例如,如果需要启动一个将跟踪数据保存到表的跟踪,同时希望在该表变得过大时停止跟踪,则可以使其自动停止。
如果已指定并且达到了最大行数,将在运行 SQL Server Profiler的同时继续运行跟踪,但不再记录跟踪信息。SQL Server Profiler将继续显示跟踪结果,直到跟踪停止
5.启用跟踪停止时间
启用跟踪停止时间之后,到了指定的时间跟踪自动停止。每一次跟踪建议都必须得设置一个跟踪停止时间防止忘记关闭跟踪导致服务器空间被占满,默认跟踪1小时。
注意:
- 从 SQL Server 2005 开始,服务器以微秒(百万分之一秒或 10-6 秒)为单位报告事件的持续时间,以毫秒(千分之一秒或 10-3 秒)为单位报告事件使用的 CPU 时间。
- 在 SQL Server 2000 中,服务器以毫秒为单位报告持续时间和 CPU 时间。
- 在 SQL Server 2005 及更高版本中,SQL Server Profiler图形用户界面默认以毫秒为单位显示“持续时间”列,但是当跟踪保存到文件或数据库表中之后,将以微秒为单位在“持续时间”列中写入值。
二、事件选择
对于不同跟踪选择不同的跟踪事件;通过勾选“显示所有跟踪事件”可以看到所有的跟踪事件,总共有21个事件分类。用得最多的两个分类就是存储过程和TSQL这两个分类主要用来记录执行的存储过程和SQL语句,把鼠标移动到具体的事件上面会显示该事件和事件列的具体说明,接下来就分析几个常用的事件和常用的事件列。
1.显示所有跟踪事件
勾选之后会将所有的事件都显示出来
2.显示所有列
勾选之后会将所有的列显示出来
3.列筛选
对列增加一些条件,其实可以将它理解在TSQL语句的WHERE后面添加条件,对于整形列直接输入数值即可,对于字符串列就相当于like一样使用不带引号的%%模糊匹配方法。通过勾选“排除不包含值的行”之后跟踪结果就会筛选掉不满足条件的记录。
4.列组织
列组织可以理解成TSQL语句里面做GROUP BY操作,可以将相同的条件放在一起去重。
事件
1.SQL:Stmt*******
[SQL:StmtStarting]:启动TSQL语句时记录
[SQL:StmtCompleted]:完成TSQL语句时记录

这两事件的区别也同单词的意思一样,StmtStarting是记录事件的开始不关注这个事件在接下来会做什么,StmtCompleted是记录事件结束之后在开始和结束这个过程中做的一些操作比如一些常用的列"Duration","Cpu","Reads","Writes","EndTime"这些列就会出现在StmtCompleted事件中。所以如果你需要收集的记录不关心整个事件过程中的操作只需要收集数量那么可以使用Starting事件比如记录某个语句或者存储过程执行的次数等。
2.SQL:Batch******
[SQL:BatchStarting]:启动TSQL批处理时记录
[SQL:BatchCompleted]:完成TSQL批处理时记录
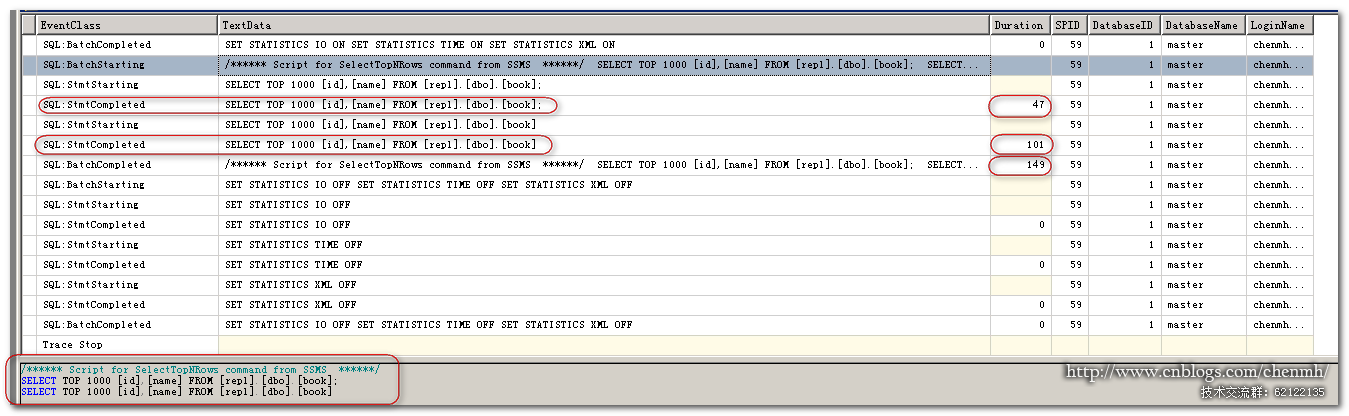

这次我把两个select语句放在一起来执行,可以从batch事件中可以看到它记录的整个批处理的SQL同时还包括相关注释,同时整个批处理两个TSQL作为一条事件记录,而stmt事件记录具体的TSQL语句把两个TSQL语句作为两条记录来记录。同时还可以发现两个TSQL的Duration相加是小于整个批处理的duration的,这也是正常的整个批处理在sql编译分析执行这块肯定比单个TSQL需要耗费更多的时间,但是相差也是非常的小。
batchcompleted事件多用于引擎优化顾问,而stmtcompleted事用于分析单个TSQL语句。同样Stored分类里面的starting事件和completed事件和TSQL里面的是一样的意思。
事件列
列举常用的事件列
TextData:文本详细信息,比如详细的执行SQL语句等等。
ApplicationName:连接SQLSever的客户端应用程序名称。
NTUserName:windows用户名
LoginName:SQLServer登入用户名。
CPU:事件占用的CPU时间,在图形化界面但是是毫秒(千分之一秒或 10-3 秒),在文本文件或者数据库表中单位是微妙(百万分之一秒或 10-6 秒)。
Reads:执行逻辑读的次数。
Writes:物理磁盘写入的次数。
Duration:事件的持续时间,也就是统计信息里面显示的占用时间,在图形化界面但是是毫秒(千分之一秒或 10-3 秒),在文本文件或者数据库表中单位是微妙(百万分之一秒或 10-6 秒)
ClientProcessID:调用SQLServer的应用程序进程ID。
SPID:SQLServer为连接分配的数据库进程ID,也就是sys.processes里面记录的进程ID。
StartTime:事件的开始时间。
EndTime:事件的结束时间。
DBUserName:客户端的sqlserver用户名。
DatabaseID:如果指定了USE database就是指定的数据库id,否则就是默认的数据库id(也就是master的数据库id)。所以该列的作用不是很大。
Error:事件的错误号,通常是sysmessage中存储的错误号。
ObjectName:正在引用的对象名称。
三、自带跟踪模板
工具自带了几个比较实用的跟踪模板,一般的跟踪都可以直接使用自带的跟踪模板解决,同时自己也可以创建自定义的跟踪事件和跟踪属性保存成模板供以后使用。
SP_Counts:计算已运行的存储过程数,并且按存储过程的名称进行分组统计,此模板可以分析某时间段存储过程的行为。
Standard:记录所有存储过程和T-SQL语句批处理运行的时间,当你想要监视常规数据库服务器活动时即可使用该模板,一般的跟踪需要使用该模板就可以解决,这也是默认的模板。
TSQL:记录客户端提交给sqlserver的所有T-SQL语句的的内容和开始时间,通常使用该模板用于程序调试。
TSQL_Duration:记录客户端提交给sqlserver的所有T-SQL语句批处理信息以及执行这些语句所需的时间(毫秒),并按时间进行分组,使用该模板可以分析执行慢的查询,此模板的跟踪记录可以用于数据库引擎优化顾问分析使用。
TSQL_Grouped:按提交客户端和登入用户进行分组记录所有提交给SQLServer的T-SQL批处理语句及其开始时间,此模板用于分析某个客户或者用户执行的查询。
TSQL_Locks:记录所有开始和完成的存储过程和T-SQL语句,同时记录死锁信息,此模板用于跟踪死锁。
TSQL_Replay:记录有关已发出的T-SQL语句的详细信息,此模板记录重播跟踪所需的信息,此模板可执行跌到优化,例如基准测试。
TSQL_SPs:记录有关执行的所有存储过程的详细信息,此模板可以分析存储过程的组成步骤。如果你怀疑正在重新编译存储过程,请添加SP:Recomple事件
Tuning:记录有关存储和T-SQL语句批处理的信息以及执行这些语句所需的时间(毫秒),使用此模板生产跟踪输出可用于数据库引擎优化顾问工作负载来优化索引、优化性能。此模板和TSQL_Druation相似后者是做了时间分组。
数据库引擎优化顾问
1.如果需要用数据库引擎优化顾问分析跟踪事件记录必须捕获了以下跟踪事件: